SVM介绍
为了简便,我们从二分类问题开始。
损失函数
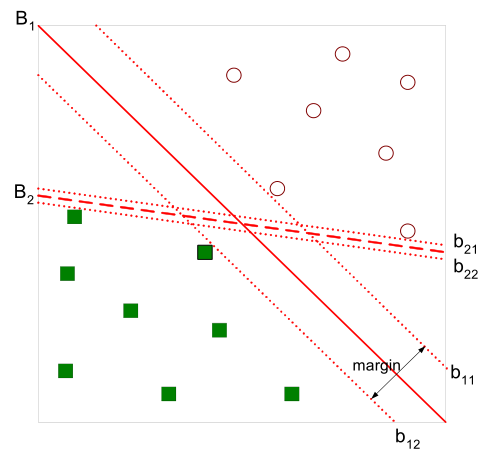
为了将绿色方块的点和红色圆圈的点分开,我们需要找到超平面(在二维空间中是线,三维是平面)。在上图中,直觉告诉我们,的线更加好,因为它对训练样本局部扰动的“容忍”性最好。
我们可以用以下的线性方程组描述:
其中就是该超平面的法向量,关于这点,我们可以任取在该超平面上的两个点,减一下得到,那么对于所决定的直线,都与它垂直,所以它就是法向量。
那么任意点到超平面的距离也就可以写成:
关于这点,我们可以这么想,任取上任意一点(过渡的中间变量),那么对于任意一点到超平面的距离为在法向量上的投影长度:
那么对于一个分类器,对一个样本我们可以令:
我们可以通过成倍的改变来改变不等式右边的值,这里固定为1便于后面计算。
那几个让等号成立的点被称为支持向量,也就是图中的和,
那么:
svm就是想要找到最大margin的超平面,现在我们可以用数学语言来描述这个需求:
用于消除正负的影响。
上面的式子又等价于(为了简便):
现在,我们有了SVM的数学描述,下面就是如何求解了。
拉格朗日乘子法
其实这就是一个凸二次优化问题,有现成的库可以直接求解,但是我们还有更优雅的数学上的解法。
”拉格朗日乘子法是一种经典的求解条件极值的解析方法,可将所有约束的优化模型问题转化为无约束极值问题的求解。“我们使用拉格朗日乘子法将上述问题转化为它的”对偶问题“,便于解决。
我们首先添加拉格朗日乘子,从而得到:
令
当所有的时,显然取到最大值,否则能够取到。所以当满足所有约束条件时,最小化就是最小化。
也就是:
这里我们是先对求最大值,之后再对求最小值。
下面我们先对求最小,再对求最大。
即:
因为最大值中的最小值肯定大于等于最小值中的最大值,所以
当满足KKT条件时, 。
此处,kkt条件应为
关于这点请参考https://www.zhihu.com/question/23311674。
简单的说,在极值点,目标函数增大的方向应该被排除在外。
因为先对求最小,那么先令和的偏导等于0:
将w和b代入原式:
经过如上的转化,我们把问题转化为了:
SMO
为了求出,我们会使用SMO算法。
针对此式,我们假设是变量,其他的是常量。那么
将带回原目标函数中,就可以消去,那么整个目标函数就是一个关于的一元二次函数。同时因为都有范围,所以可以得到的一个取值范围,在这个范围内,我们可以很快的对二次函数求最大值,即完成一次迭代。
软间隔
我们之前讨论的默认条件是数据是线性可分的。我们在样本空间中找到一个超平面将其完全分割开来,这个超平面是最大化margin来确定的。但是很多情况下,数据不是线性可分的,会有一些outlier,如果我们将这些outlier也算进去,那我们获得的超平面会有很大程度上的过拟合。
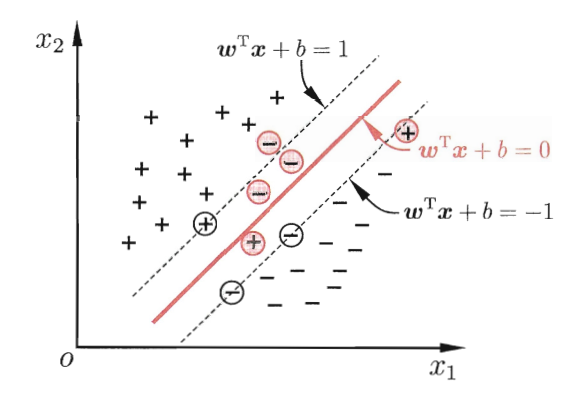
我们原来对所有的样本都要求
现在我们允许一些样本不满足上述约束,当然,这样的样本应该尽量的少。
我们改写原来的优化目标:
这里的用来控制第一项寻找margin最大的超平面和第二项保证数据量偏差最小之间的权重。上式中的$$l_{01}$$ 是一个01损失函数,我们一般使用hinge loss来替换它:
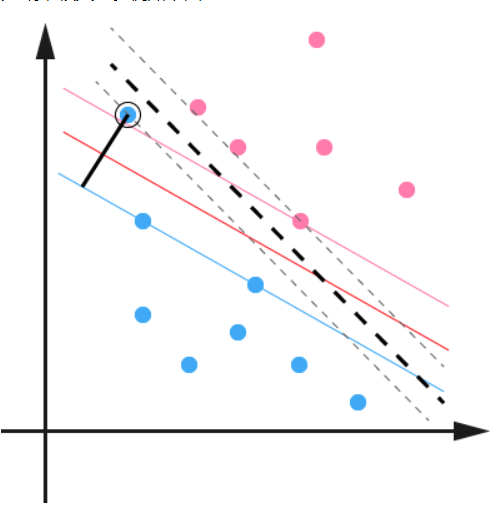
原本的分类平面是红色的线,对应的分别是蓝色和粉色的线。但是考虑到黑圈圈起来的蓝点,原来的超平面就偏移到黑色虚线那里了。
现在我们引入松弛变量 ,对应上图黑色线段,据此将约束条件改为
再重写上式
接下来同上面的拉格朗日乘子法,我们可以解得
Reference
https://www.cnblogs.com/en-heng/p/5965438.html
《机器学习》 周志华
http://blog.pluskid.org/(kid神真的写的好啊)
https://www.cnblogs.com/90zeng/p/Lagrange_duality.html
https://www.cnblogs.com/jerrylead/archive/2011/03/18/1988419.html(SMO,写的非常详细)